DALL·E 2 vs $10 Fiverr Commissions

Recently I wrote a blog post that had a concept I wanted to show graphically. Given that my drawing skills are terrible, I turned to Fiverr to get something that didn’t make my eyes bleed. While waiting for my commissioned art, I realized this was the perfect opportunity to compare the state of the art image generation models to what $10 got me on Fiverr (well, 12.55 with the service fee).
First, I needed to describe what I had in mind purely in words. I settled on this:
A graph with 3 slightly wavy lines: the first (labelled morality, colored green) starts near the top and goes down. The second (labelled legality, colored blue) starts near the bottom and goes up. The third (labelled prosecution, colored red) starts below the second, and generally follows the second (always remaining below the second). The three lines should converge close to each other by the end. There should be a point where the first line goes below the second, and then it goes back above. The first line should still be above the third line. The bottom axis should be labelled as time, with an arrow pointing to the right. In the middle of the graph, there should be a vertical line (labelled privacy, colored black) that goes between the first line and the third line.
(To get more context, read the post.)
However, this was already too long for DALL·E 2 and Stable Diffusion. So I trimmed it down to the following:
A graph with 3 slightly wavy lines: the first (labelled morality, colored green) starts near the top and goes down. The second (labelled legality, colored blue) starts near the bottom and goes up. The third (labelled prosecution, colored red) starts below the second, and generally follows the second (always remaining below the second). The three lines should converge close to each other by the end.
DALL·E 2 Results
Note: DALL·E 2’s maximum length cut off the period from the prompt. Not sure if this made a large difference.
Pretty lame. Only 50% of the results are even graphs of lines at all. Let down, I decided to try out Stable Diffusion in hopes that it could do better.
Stable Diffusion Results
(via beta.dreamstudio.ai with width: 512, height: 512, cfg scale: 20, steps: 150, images: 4, sampler: k_lms, model: stable diffusion v1.5)
Somehow even worse than DALL·E 2.
Fiverr Person #1
Okay, well maybe it was impossible for anyone to deduce what I was trying to convey. Let’s see what my first $10 commission gave me (keep in mind this is with the unabridged prompt):
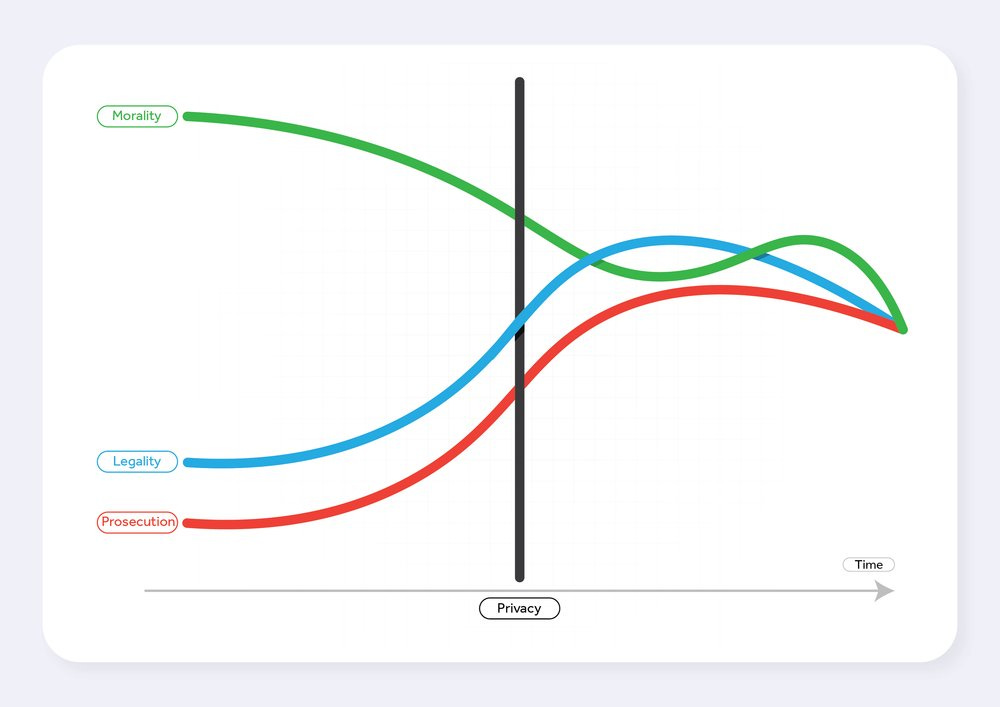
I feel the sanity returning to me… However, it seems they didn’t catch the part where I said the black line should go between the first and third lines. Trying my hand at some prompt engineering, I tweaked the prompt to
A graph with 3 slightly wavy lines: the first (labelled morality, colored green) starts near the top and goes down. The second (labelled legality, colored blue) starts near the bottom and goes up. The third (labelled prosecution, colored red) starts below the second, and generally follows the second (always remaining below the second). The three lines should converge close to each other by the end. There should be a point where the first line goes below the second, and then it goes back above. The first line should still be above the third line. The bottom axis should be labelled as time, with an arrow pointing to the right. In the middle of the graph, there should be a vertical line (labelled privacy, colored black) that starts at the first line and ends at the third line.
(Bolded to emphasize the difference.) I commissioned another piece with this new prompt, and here is the result:
Fiverr Person #2
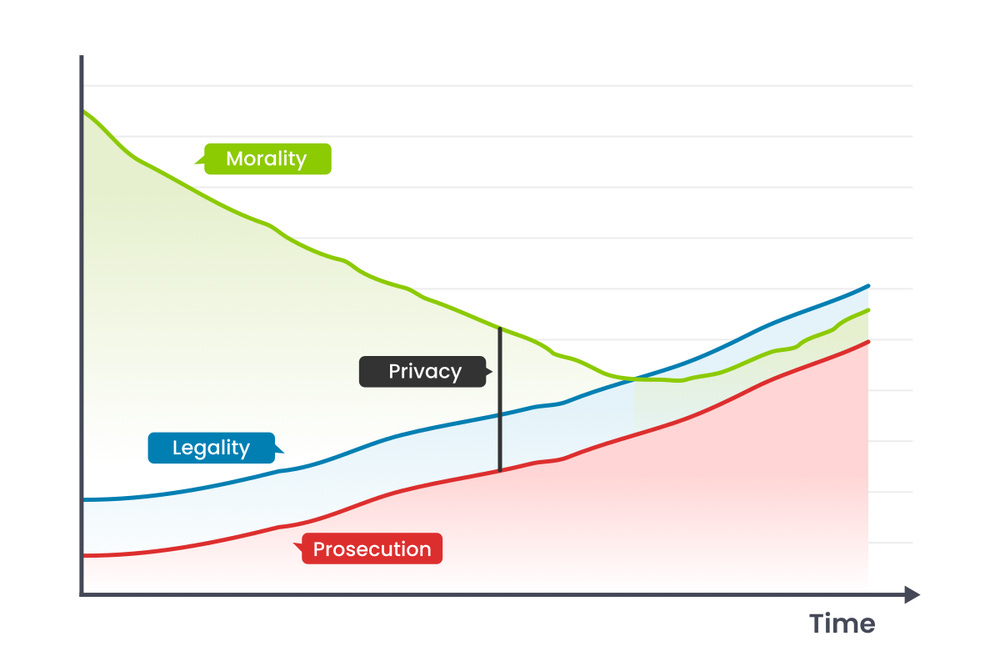
It seems like my prompt engineering worked, but at the same time this Fiverr person forgot to make the first line go back above the second.
Sketch-inspired Drawings
Stable Diffusion has a neat feature where you can upload an image as inspiration. In fact, this is what you usually do on Fiverr. Here is the sketch I uploaded to Stable Diffusion:
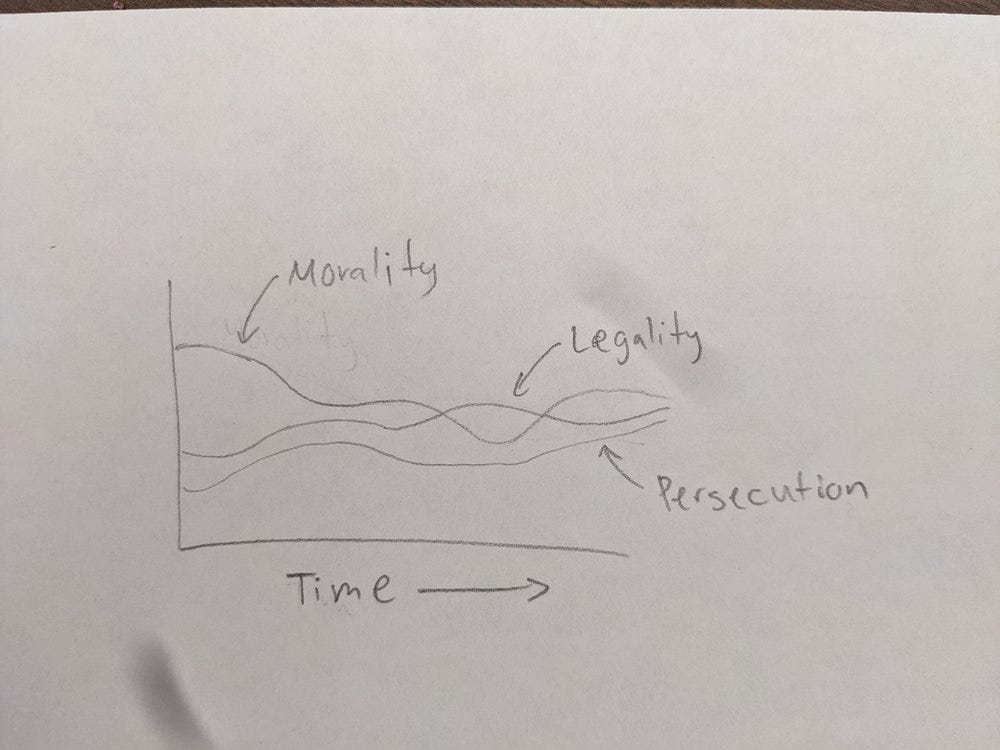
and here is what Stable Diffusion did to my poor baby (via beta.dreamstudio.ai with width: 512, height: 512, cfg scale: 20, steps: 150, images: 4, sampler: k_lms, model: stable diffusion v1.5, image similarity: 50%):

Here’s how the Fiverr commission came out with the abridged prompt and the same sketch as reference:
Fiverr Person #3
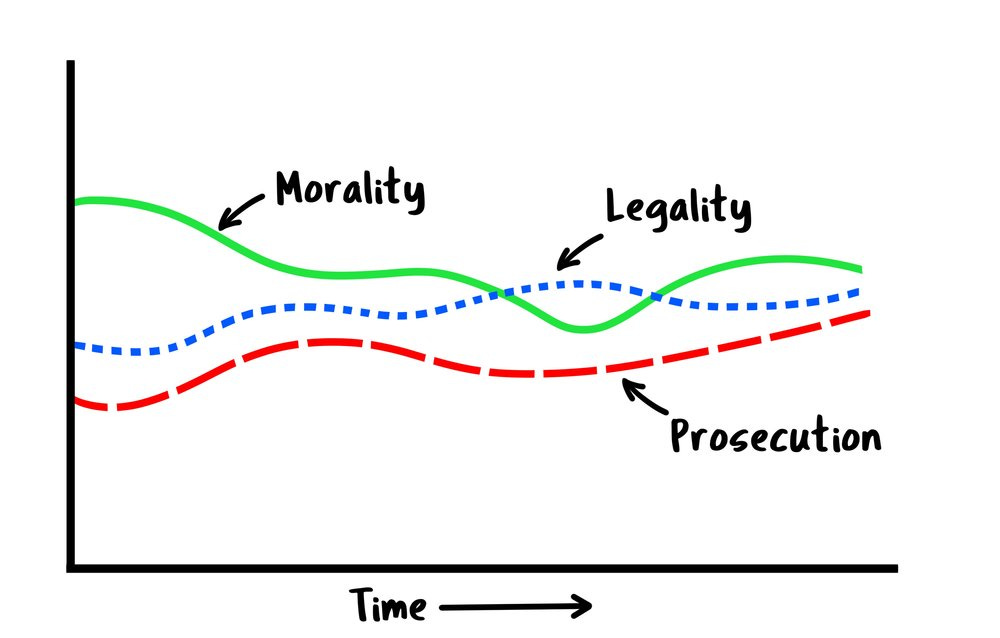
Not too shabby, eh?
(I ended up asking this person to make a few revisions for the final result, which you can see in the post!)
Minimum Viable Garbage
Maybe these models are unequipped to handle a wall of text like my trusty Fiverr friends. However, that doesn’t seem to be the case. The smallest possible prompt that still produced nonsense was
a graph with 3 lines
Here is DALL·E 2’s rendition:

To be fair there is technically one graph with 3 lines, but I wouldn’t call that passable by any stretch of the imagination.
Here is Stable diffusion’s best attempt (via beta.dreamstudio.ai with width: 512, height: 512, cfg scale: 20, steps: 150, images: 4, sampler: k_lms, model: Stable diffusion v1.5):

It seems Stable Diffusion was trained on graph paper, but it still produces garbage.
Imagen
I don’t have the clout to bully Google engineers into running my prompts (yet), so if you do have this power or are such an engineer yourself, and want to flex the supposed contextual and compositional superiority of Imagen, please be my guest and share your results!
Prompt Engineering
A fair criticism of this post would be that I spent no time on optimizing my prompts, which has been shown to make a big difference in the quality of the output. I’m skeptical of much of an improvement you could get because these results seem to come from more of a fundamental incapability of DALL·E 2/Stable Diffusion. However, if you make any progress, let me know!